Presentation 2024/05/21
The impact of artificial intelligence and Industry 4.0 ontrans forming accounting and auditing practices
phd09 上課筆記 | 論文PDF | 論文html | 簡報稿 | 備忘htw_memo |
Smart-PLS 4 可以運行在64位元的Ubuntu 22.04系統上。這是專門用於潛在變量建模的軟體,它結合了最先進的方法(例如PLS-POS、IPMA、複雜的引導程序)和易於使用的直觀圖形用戶界面。可從官網下載安裝。這是商業軟體,但有免費的30天試用版。且學生可能有資格獲得折扣。
需要讀懂的12張表Table,和3個圖 Figure。
p.5 Table 1: Sampling Adequacy Test - 檢查問卷數據是否適合進行因子分析。這個表格通常使用Kaiser-Meyer-Olkin (KMO) 測試來評估抽樣的適宜性。
p.6 Table 2: Operational Definition of the Variables - 定義研究中使用的所有變數的操作定義,以確保讀者明白每個變數的具體含義和測量方式。
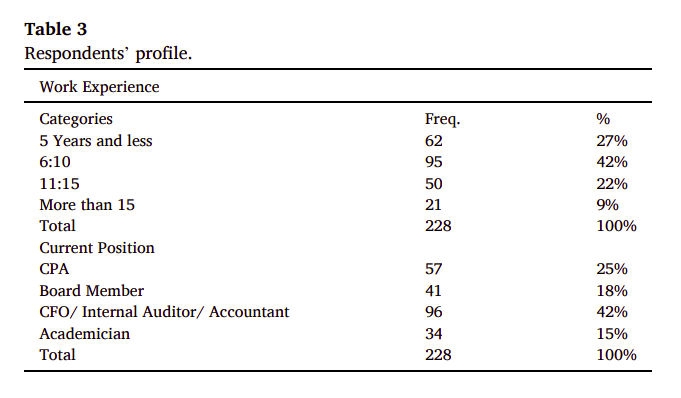
p.6 Table 3: Respondents' Profile - 提供回答問卷的受訪者的人口統計資料,如年齡、性別、職業等。
p.7 Table 4: Factor Loadings - 展示各變數在因子分析中的載荷值,用以評估哪些變數對因子有顯著的貢獻。
p.8 Table 5: Validity and Reliability for Constructs - 檢測構念的有效性和可靠性,確保研究工具的測量精確性。
p.9 Table 6: Discriminant Validity - 鑑別不同構念間的獨立性,確認每個構念與其他構念的區分度。
p.9 Table 7: Descriptive Statistics - 提供數據的描述性統計,如平均數、標準差等,以概述數據集的基本特徵。
p.10 Table 8: SEM Estimation – Direct Effect Model - 結構方程模型(SEM)的直接效果估計,分析變數間直接關聯的強度和方向。
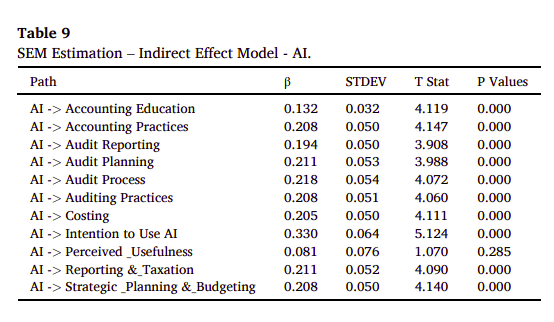
p.11 Table 9: SEM Estimation – Indirect Effect Model - AI - 通過人工智能(AI)分析間接效果,探討AI如何影響其他變數。
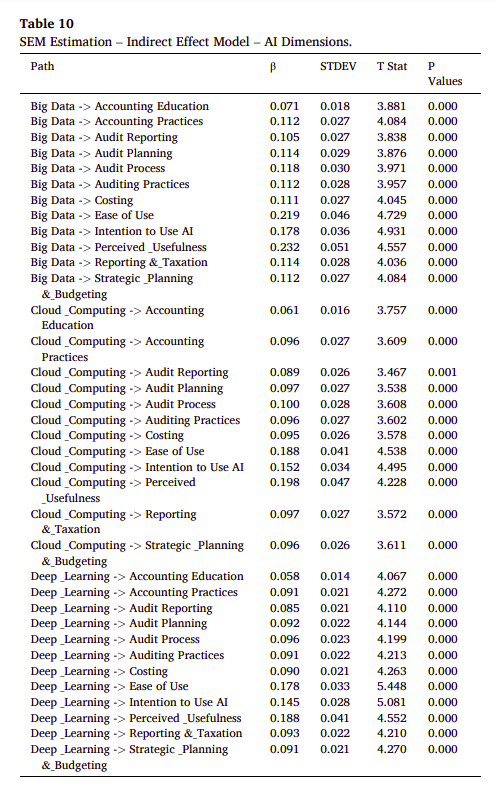
p.11 Table 10: SEM Estimation – Indirect Effect Model – AI Dimensions - 分析AI各個維度的間接效果,了解不同AI屬性對結果變數的影響。
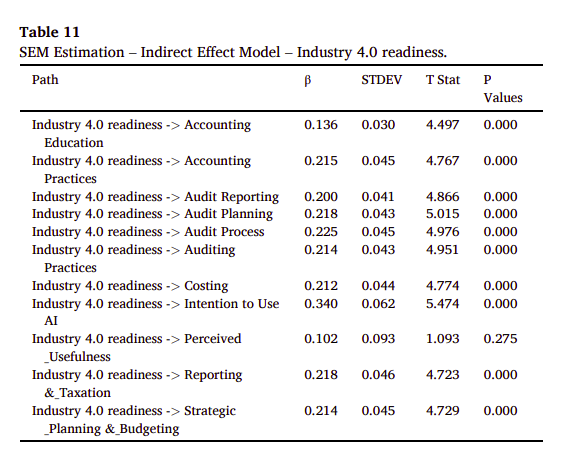
p.11 Table 11: SEM Estimation – Indirect Effect Model – Industry 4.0 Readiness - 探討產業4.0準備程度對其他變數的間接影響。
p.12 Table 12: SEM Estimation – Indirect Effect Model – TAM Dimensions - 分析技術接受模型(TAM)各維度的間接效果,評估它們如何影響總體模型。
p.5 Fig. 1: Research Framework - 展示研究的整體框架,說明研究變數之間的假設關係。
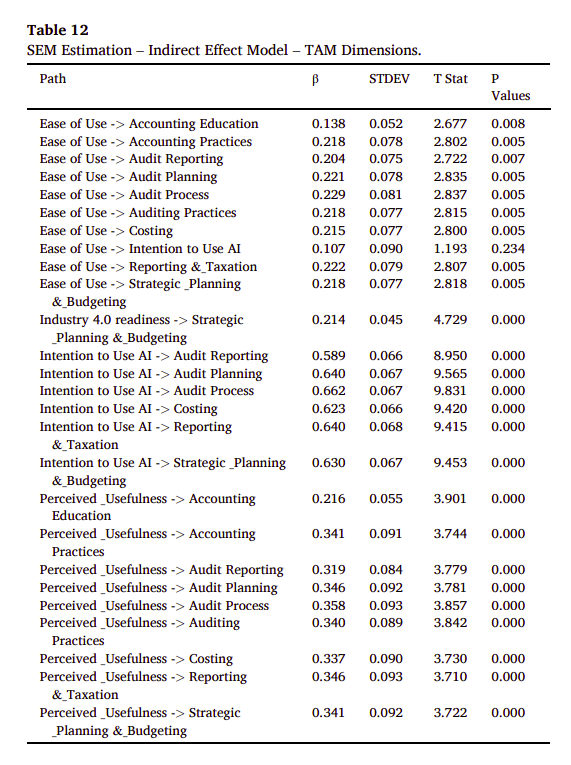
p.8 Fig. 2: Confirmatory Factor Analysis - 確認性因子分析的視覺表示,用以驗證變數之間的假設因子結構。
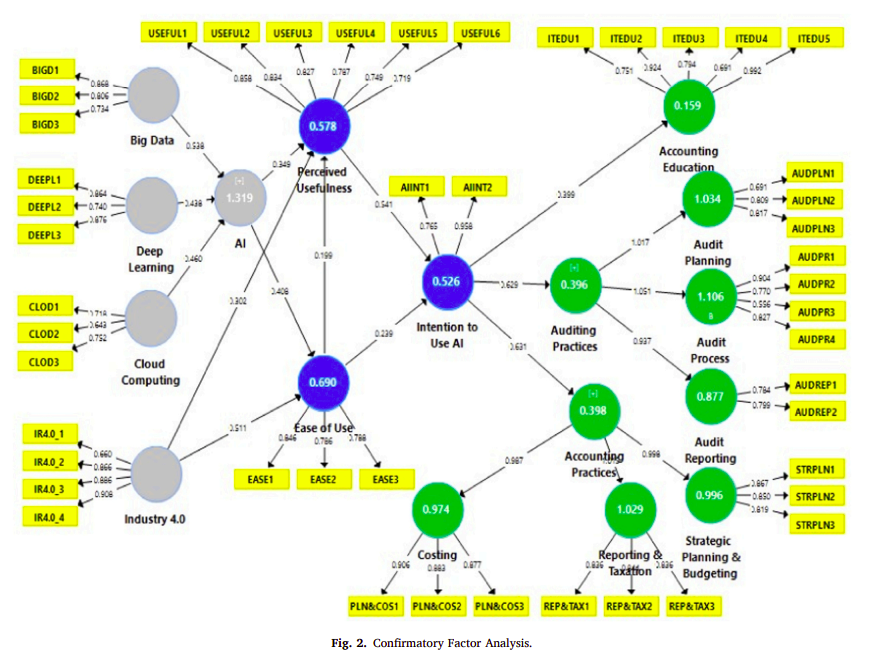
p.10 Fig. 3: Structural Equation Model- Direct Effect - 結構方程模型的視覺呈現,專注於變數間的直接影響。
抽樣方法Sampling method:
方便抽樣convenience sampling和雪球抽樣snowball sampling methods 法
方便抽樣(convenience sampling)是一種非概率抽樣方法,研究者因為容易接觸到而選擇樣本單位。這可能是因為地理位置近、在特定時間可用或願意參與研究。這種抽樣方法有時被稱為偶然抽樣,是非隨機抽樣的一種。
雪球抽樣(snowball sampling)也是一種非概率抽樣方法,新的樣本單位是通過其他單位招募來的。這種方法對於研究特定特徵的人群很有用,這些人群可能很難以其他方式識別(例如,患有罕見疾病的人)。雪球抽樣通常從一個或多個研究參與者開始,然後根據這些參與者的推薦繼續進行。這個過程持續進行,直到達到所需的樣本大小或飽和點。
這兩種抽樣方法都有其優點和局限性,選擇使用哪一種取決於研究的具體需求和條件。
1.請舉例說明,為何需要做「Sampling Adequacy Test」因子分析?如何做?如可理解分析的結果?
1. Please give an example, why is it necessary to do “Sampling Adequacy Test” factor analysis? How to do? How can the results of the analysis be understood?
在統計分析中,「Sampling Adequacy Test」,例如Kaiser-Meyer-Olkin (KMO) 測試,是用來評估數據是否適合進行因子分析的一種方法。這個測試通過比較變量間的偏相關和簡單相關,來衡量變量之間共享信息的多少,從而判斷數據集是否適合進行因子分析。
為何需要做KMO測試? KMO測試可以幫助我們了解變量之間的共性,即變量間共享的信息量。如果變量之間的共性高,則進行因子分析是有意義的,因為這意味著存在一些潛在的因子可以解釋這些變量間的相關性。KMO值越接近1,表示數據對因子分析的適應性越強。如果KMO值低於0.5,則數據可能不適合進行因子分析。
如何進行KMO測試? KMO測試的計算公式為: $$ KMO = \frac{\sum\sum a{ij}^2}{\sum\sum a{ij}^2 + \sum\sum b{ij}^2} $$ 其中 ( a{ij} ) 表示第i個和第j個變量的相關性,( b_{ij} ) 表示第i個和第j個變量的偏相關性。這個指標比較了觀察到的相關係數值與偏相關係數值,從而提供了一個對數據進行因子分析的初步判斷。
如何理解分析的結果?
KMO值的範圍是0到1。KMO值的解讀如下:
• 0.00到0.49:不可接受
• 0.50到0.59:差
• 0.60到0.69:一般
• 0.70到0.79:中等
• 0.80到0.89:良好
• 0.90到1.00:優秀
如果KMO值接近1,則表明變量間的相關性強,因子分析可能會得到有意義的結果。如果KMO值低,則表明變量間的相關性弱,進行因子分析可能不合適。
需要注意的是,KMO值只是一個參考指標,並不能代替對數據本身和研究設計的深入理解。因子分析的適用性取決於許多因素,包括數據的性質(例如,數據的分布和規模)以及研究問題的具體性質。因此,不能僅憑KMO值決定是否進行因子分析。
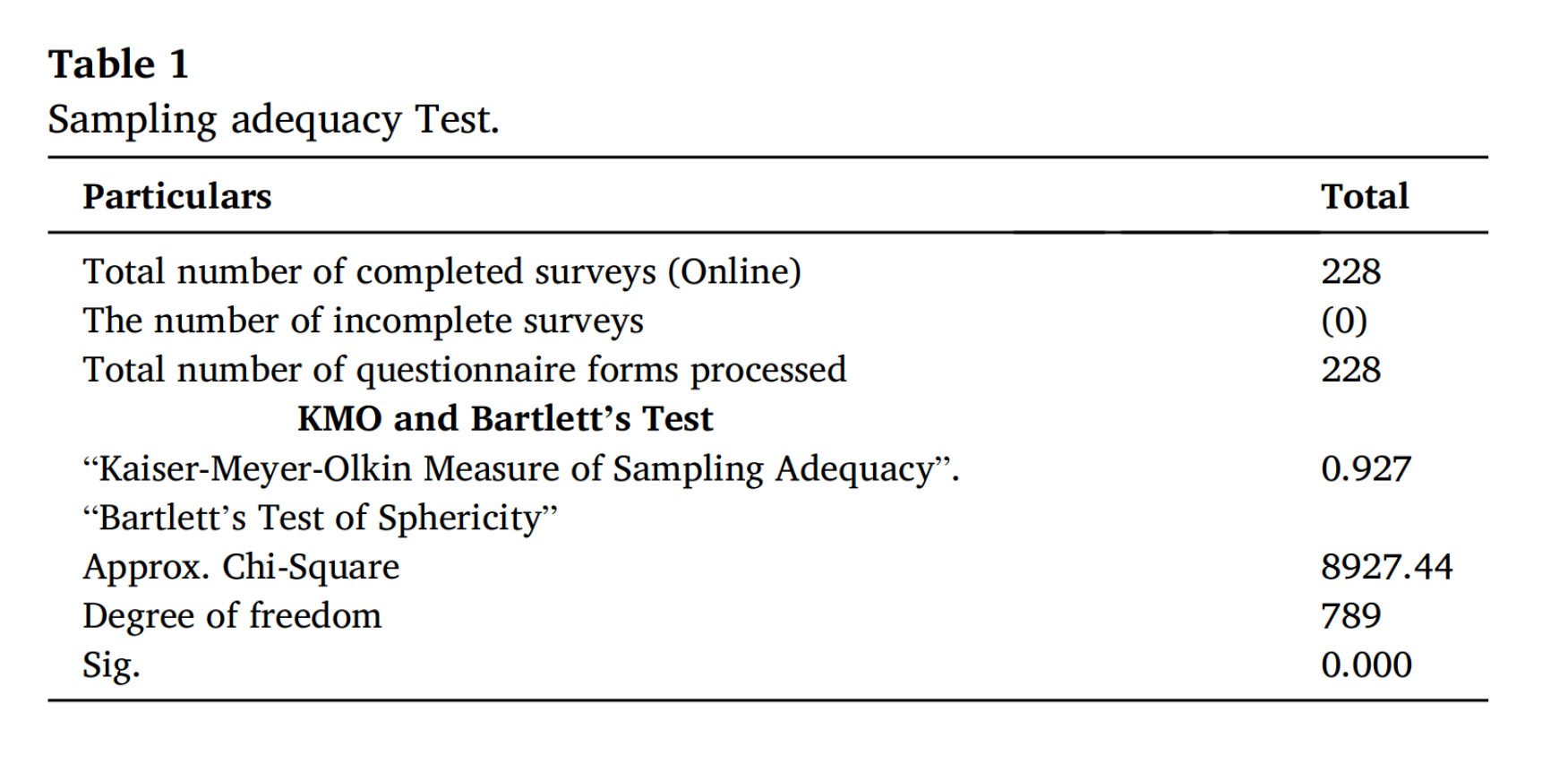
• 完成處理的總數量: 228
• KMO 測量: 0.927
• Bartlett’s Test of Sphericity:
• 近似卡方值 (Approx. Chi-Square): 8927.44
• 自由度 (Degree of freedom): 789
• 顯著性 (Sig.): 0.000
這些結果的意義如下:
• KMO 測量的值為 0.927,這是一個非常高的值,表明變量之間有很高的共同變異數,這意味著數據非常適合進行因子分析。
• Bartlett’s Test of Sphericity 產生了一個非常高的 近似卡方值 (8927.44) 和一個相對大的 自由度 (789)。這表明變量之間的相關性非常強,不太可能是隨機產生的。
• 顯著性 (Sig.) 的值為 0.000,這通常表示結果具有極高的統計顯著性。這意味著我們可以拒絕零假設,即變量之間沒有相關性,並且確認變量之間確實存在相關性。
總體來說,這份報告表明數據集非常適合進行因子分析,因為變量之間存在顯著的相關性,且數據的共同變異數很高。這是進行因子分析的良好前提,因為它表明數據中有潛在的結構,可以通過少數幾個因子來解釋。
4: 請舉例說明,為何需要做 Factor Loadings test,這個Test如何 展示各變數在因子分析中的載荷值,如何評估哪些變數對因子有顯著的貢獻。
4: Please give an example of why a Factor Loadings test is needed, how this test displays the loading values of each variable in factor analysis, and how to evaluate which variables make a significant contribution to the factors.
(或看 Paper Table1. 後面的 Model’s measurement
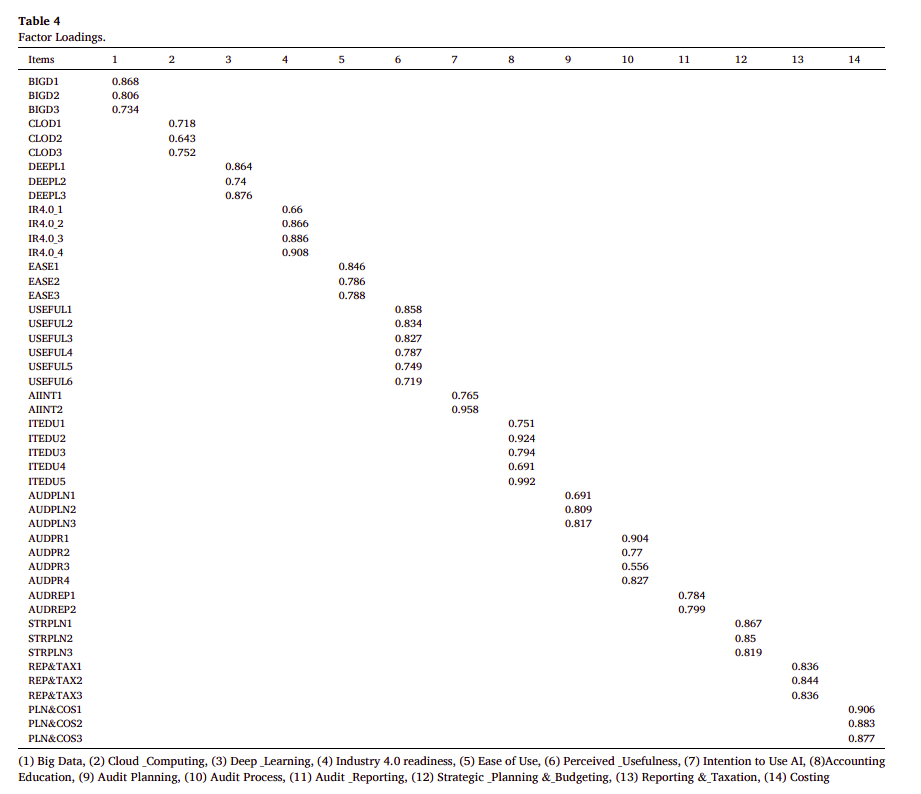
在因子分析中,因素負荷量(Factor Loadings)是衡量個別變數與因素之間相關性的指標。這個指標的數值介於-1至1之間,類似於Pearson相關係數。因素負荷量的平方表示該因素可以解釋該變數多少的變異量。例如,如果一個變數的因素負荷量是0.4,則該因素可以解釋該變數16%的(0.4的平方是0.16)變異量。
為何需要做Factor Loadings test? 進行因素負荷量測試可以幫助我們識別哪些變數與特定因素有強烈的關聯。這對於理解變數如何組合成因素,以及每個因素代表的概念是非常重要的。
如何展示各變數在因子分析中的載荷值? 因素負荷量通常在因子分析的輸出中以表格形式呈現,每個變數對於每個因素都會有一個負荷量值。這些值顯示了變數與因素之間的關聯強度。
如何評估哪些變數對因子有顯著的貢獻? 一般來說,因素負荷量的絕對值越大,表示該變數對因素的貢獻越大。根據Hair et al. (1992)的建議,因素負荷量低於0.4通常被認為是太低,而0.6以上則被認為是高的。但這些只是一個準則,最終決定一個變數是否對一個因素有顯著貢獻還需要考慮理論和研究設計。
在實際應用中,研究者可能會根據他們的研究目的和樣本的特性來設定不同的閾值。有時候,即使因素負荷量低於0.4,如果該變數在理論上是重要的,研究者也可能選擇保留該變數。同樣地,驗證性因子分析(CFA)中,一些研究者可能會設定更高的標準,例如因素負荷量低於0.5或0.7就刪除該題項。
總之,因素負荷量測試是因子分析中一個關鍵的步驟,它幫助我們了解變數如何在不同因素之間分配,並評估每個變數對因素的貢獻程度。這些信息對於解釋因子分析結果和進一步的研究分析至關重要。
5: 請舉例說明,為何需要做 Validity and Reliability for Constructs - 如何解讀?與如何評估這個Test所展示的數據?
5: Please give an example of why it is necessary to do Validity and Reliability for Constructs - how to interpret it? How to evaluate the data displayed by this Test?
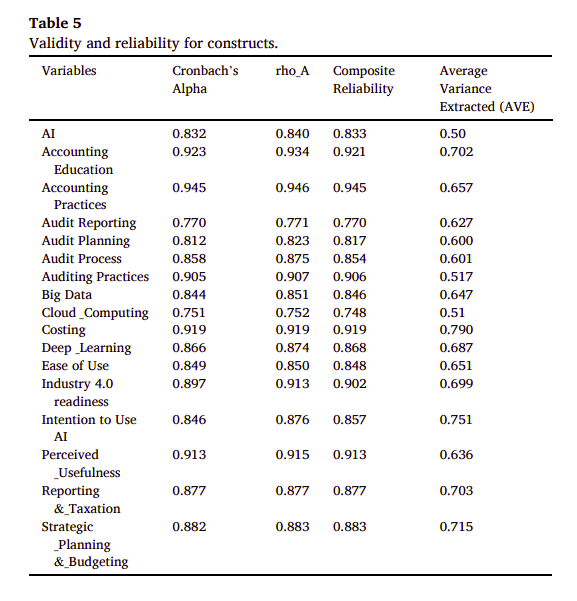
在進行因子分析時,構念的效度(Validity)和信度(Reliability)是非常重要的概念。這些概念確保我們的測量工具能夠準確地衡量我們想要研究的構念。
為何需要做構念的效度和信度測試?
• 效度(Validity):指的是測量工具是否能夠準確地衡量預定的構念。例如,如果我們想要測量「工作滿意度」,我們需要確保問卷中的題目真正反映了工作滿意度的各個方面,而不僅僅是薪資滿意度。
• 信度(Reliability):指的是測量工具在重複測量時的一致性和穩定性。高信度意味著如果我們多次使用同一測量工具,應該會得到相似的結果。
如何解讀效度和信度測試?
• 效度可以通過多種方式來評估,例如內容效度、構念效度和區分效度。構念效度通常通過因子分析來評估,確保測量工具所測量的是理論上預期的構念。
• 信度通常通過計算Cronbach’s α係數來評估。α係數越高,信度越好。一般來說,α係數高於0.7被認為是可接受的。
如何評估這個測試所展示的數據?
• 當我們看到一個高的構念效度時,這意味著測量工具與理論構念之間有強烈的關聯。這可以通過因子負荷量來展示,如果一個變數對應的因子負荷量很高,這表明它與構念有強烈的關聯。
• 信度的評估則是看α係數的值。如果α係數接近1,這表明測量工具非常一致和穩定。如果α係數低於0.7,則可能需要重新考慮測量工具的設計。
總的來說,進行構念的效度和信度測試是確保我們的研究結果可靠和有效的關鍵步驟。這些測試幫助我們理解和評估測量工具的質量,並確保我們的研究結果能夠準確地反映我們想要研究的構念。
- Evaluating a Scale’s Construct Validity to Assess the Group Work Environment Using the Rasch Model
- GradCoach Validity & Reliability In Research
- 永析統計諮詢-信效度分析基本介紹
6: 請舉例說明,為何需要做 Discriminant Validity - 如何解讀?與如何評估這個Test所展示的數據?
6: Please give an example why Discriminant Validity is required - how to interpret it? How to evaluate the data displayed by this Test?
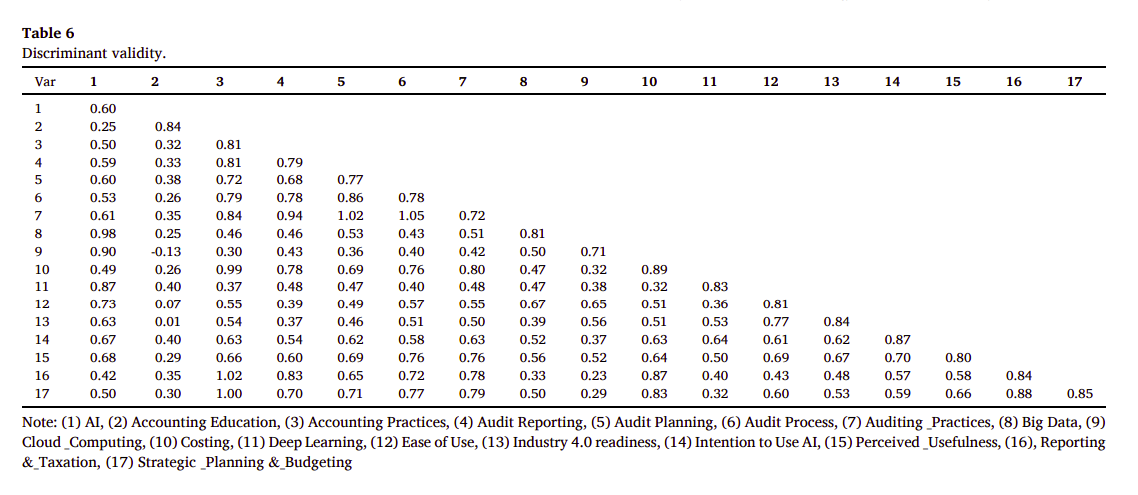
區分效度(Discriminant Validity)是構念效度(Construct Validity)的一部分,它用於評估不同構念之間是否相互獨立。區分效度的高低反映了測量工具能否準確地區分不同的概念或變量。
為何需要做區分效度測試?
區分效度測試確保每個構念都是獨特的,並且不會與其他構念混淆。這對於理論模型的驗證非常重要,因為它可以顯示出測量工具是否能夠區分那些理論上應該不相關的構念。
如何解讀區分效度測試?
區分效度通常通過比較構念間的相關性來評估。如果不同構念之間的相關性低,則表明具有良好的區分效度。一種常見的方法是使用平均變異提取量(AVE)的平方根與其他構念的相關係數進行比較。如果AVE的平方根大於相關係數,則認為具有良好的區分效度。
如何評估區分效度測試所展示的數據?
在實際操作中,研究者會建立一個矩陣,將AVE的平方根放在對角線上,並將不同構念間的相關係數填入非對角線位置。如果對角線上的數值(AVE的平方根)大於其所在行和列的其他數值(相關係數),則認為測量工具在這些構念上具有良好的區分效度。
例如,假設我們有兩個構念A和B,A的AVE的平方根是0.8,B的AVE的平方根是0.7,而A和B之間的相關係數是0.5。由於AVE的平方根大於相關係數,我們可以說,這兩個構念在區分效度上是合格的。
總結來說,區分效度測試是一個重要的步驟,它幫助我們確認測量工具是否能夠區分不同的構念,從而保證研究結果的準確性和可靠性。這個測試的結果可以通過數據矩陣來直觀地展示,並且通過比較AVE的平方根和相關係數來進行評估。
峰度(Kurtosis):峰度是衡量數據分布峰部的尖銳程度以及尾部厚度的統計量。峰度反映了數據分布的高低與平坦程度。
• 正峰度(Kurtosis > 0):表示數據分布比正態分布更尖銳,尾部較厚,意味著數據中存在較多的極端值。
• 零峰度(Kurtosis = 0):表示數據分布的形狀與正態分布相似。
• 負峰度(Kurtosis < 0):表示數據分布比正態分布更平坦,尾部較薄,意味著極端值較少。
偏度(Skewness):偏度是衡量數據分布非對稱程度的統計量,它反映了數據分布的對稱性。
• 正偏度(Skewness > 0):表示數據分布的尾部向右延伸,多數數據集中在均值左側,即分布的右側尾部較長。
• 零偏度(Skewness = 0):表示數據分布是對稱的,類似正態分布。
• 負偏度(Skewness < 0):表示數據分布的尾部向左延伸,多數數據集中在均值右側,即分布的左側尾部較長。
這兩個指標對於描述數據集的整體形狀非常有用,特別是在進行數據分析和模型建立時,可以提供有關數據分布特性的重要信息。
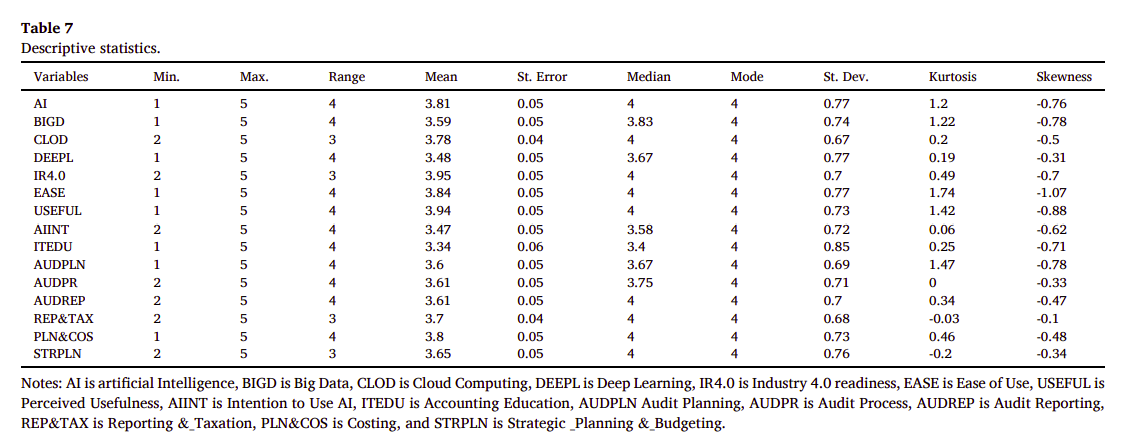
以下是針對Table 數據的解讀。
Table 7每個變量的分布特性進行以下解讀:
範圍(Range): 大部分變量的範圍是4,表示數據在最小值和最大值之間的變化範圍。
中位數(Median)和眾數(Mode): 大部分變量的中位數和眾數都是4,這表明數據的中心趨向於較高的值。
標準差(St. Dev.): 所有變量的標準差都在0.67到0.85之間,這表示數據點圍繞著平均值的分散程度是適中的。
峰度(Kurtosis):
• 大部分變量的峰度值都大於0,表示這些變量的分布比正態分布更尖銳,尾部較厚。這意味著數據中存在一些極端值。
• 特別是變量EASE的峰度值為1.74,顯示出相對較高的尖峰特性和厚尾現象。
• 變量AUDPR的峰度值為0,表示其分布形狀與正態分布相似。
偏度(Skewness):
• 所有變量的偏度值都小於0,表示數據分布的尾部向左延伸,即分布的左側尾部較長,多數數據集中在均值右側。
• 變量EASE的偏度值為-1.07,是所有變量中最小的,顯示出明顯的左偏分布,即數據向左尾部集中的程度較高。
總體來看,這些變量的數據分布呈現出輕微的左偏和尖峰特性。這些信息對於理解數據的整體分布和進行後續的數據分析非常有用。
8: 請舉例說明,為何需要做 SEM Estimation – Direct Effect Model - 如何解讀?與如何評估這個Test所展示的數據。
8: Please give an example, why do you need to do SEM Estimation – Direct Effect Model - how to interpret it? and how to evaluate the data displayed in this Test
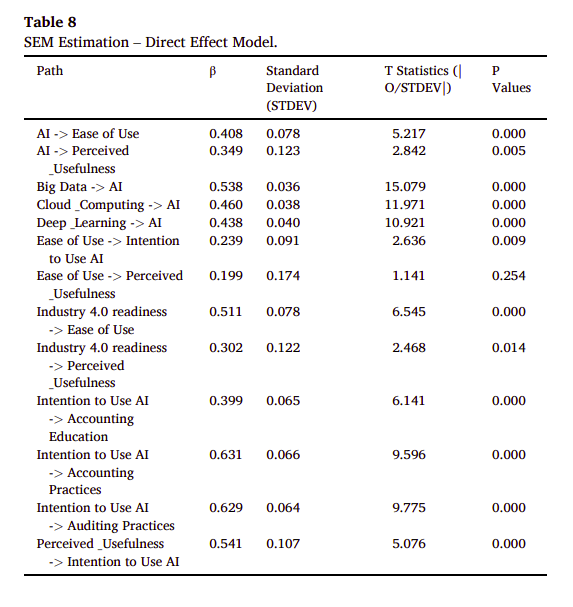
結構方程模型(SEM)估計中的直接效應模型是用來評估變數之間直接關聯的強度。這個模型可以幫助我們了解一個變數對另一個變數的直接影響,而不考慮任何中介變數的作用。
為何需要做SEM直接效應模型估計?
直接效應模型估計可以揭示變數之間的直接關係,這對於理解變數如何直接相互作用非常重要。例如,在教育研究中,我們可能想知道家長焦慮(PA)直接對孩子焦慮(CA)有多大的影響,而不是通過家長過度控制(PO)這一中介變數。
如何解讀SEM直接效應模型的結果?
在SEM的直接效應模型中,我們會看到每個變數對另一個變數的直接影響的估計值。這些估計值通常會以標準化的係數(β)來表示,這樣可以更容易地比較不同變數之間的效應大小。
如何評估這個測試所展示的數據?
評估SEM直接效應模型的數據時,我們需要考慮以下幾點:
• 效應大小:直接效應的係數大小可以告訴我們一個變數對另一個變數的影響有多大。
• 統計顯著性:通過檢驗直接效應的p值,我們可以判斷這個效應是否在統計上顯著。
• 模型適配度:整個模型的適配度指標,如RMSEA、CFI等,可以告訴我們模型與實際數據的契合程度。
例如,如果我們有一個模型估計家長焦慮對孩子焦慮的直接效應為0.3,並且這個效應在統計上是顯著的(p < 0.05),那麼我們可以說家長焦慮對孩子焦慮有中等程度的直接正面影響。如果模型的適配度指標也顯示良好的模型適配,那麼我們可以對這個結果有更多的信心。
Software semEff 0.61
Books Direct, Indirect, and Total Effects
Discussing Estimation of direct and total effects with regressions and SEM (lavaan)。
總之,SEM的直接效應模型估計是一個強大的工具,它可以幫助我們理解變數之間的直接關係,並評估這些關係的強度和顯著性。這對於建立和驗證理論模型非常有價值。
應用數學包括許多不同的數學分支,例如:
• 線性代數:研究向量空間和線性方程組。
• 微分方程:描述物理、工程或其他科學問題中的變化率和動態系統。
• 統計學和機率論:用於數據分析和風險評估。
• 數值分析:數學算法的數值解。
• 最優化:尋找最佳解決方案的數學方法。
此外,應用數學還包括將數學應用於特定問題,如密碼學中的數論應用、經濟學中的賽局理論應用,以及計算機科學中的算法和數據結構的應用。隨著科學和技術的進步,應用數學的範圍和影響力也在不斷擴大。
PLS-SEM
Composite-based path是指基於組合模型的路徑分析。此分析法主要用於估計具有多個依賴和獨立變量的模型。與傳統的PLS-SEM不同,composite-based path分析是一步法,它使用等權重指標(在每個構造有多個測量時),並且在未標準化的數據上操作。
在Smart-PLS中,當變量基於多個指標時,這些指標被賦予相同的權重以獲得構造分數。原則上,只對觀察到的變量(或等權重構造)之間的結構關係進行建模,無論是否包含控制變量。這種模型經常用於一個或多個變量要中介兩個其他變量之間的關係(中介模型)。同時,也可以建模調節中介。
Path Analysis and PROCESS
SmartPLS中的引導程序(bootstrapping)使得路徑模型的顯著性測試成為可能。因此PROCESS模塊提供了所有傳統上為PROCESS提供的建模和計算選項。
總的來說,composite-based path分析是一種靈活的統計技術,用於估計和測試理論模型中變量之間的因果關係。它適用於那些旨在探索變量之間複雜關係的研究,特別是當模型中包含多個中介和調節效應時。
課程:巨大數據6 小時SmartPLS課程
這篇很好,PLS很簡單! SmartPLS易上手!使用教學懶人包
Smart-PLS 易上手!!PLS -Partial Least Squares 其實很簡單!
估計與檢驗你的結構模型
1、選擇演算法
PLS Algorithm: FIMIX-PLS, Bootstrapping, Blindfolding;
2、演算法設定,點選後會看到以下畫面
演算法設定-apply missing valule agorithm處理選定(mean replacement, or case wise replacement刪掉)-
PLS Algorithm Settings [Weighting scheme]請選擇Path weighting scheme,
再來data metric,選預設,這是將資料做標準化,把資料轉換成標準常態分配,也就是mean=0,STDEV標準差=1的分配,不用動它。
Maximum Iterations也不動他,這是指在估計參數時最多跑300回停止,因PLS是反覆的估計latent construct scores (潛在概念分數)而來的,所以這邊才會要設定最高跑幾次,因為如果收斂不了,電腦也會自動停下來。
再來Abort Criterion,這是科學記號0.00001,跟剛才一樣,是收斂的停止條件。
最後是initial weights,直接用預設值1就行了。選取完之後選擇finish。
3、檢視你的估計結果
Step 1:
- Construct 內有Composite reliability,和R square 兩個指標。
- R square,並沒有一個標準,視不同領域而討論之,R square值無關顯不顯著,只是告訴你,你的自變數能解釋依變數的程度,從0~1,0代表你的自變數跟依變數完全無關,1代表你的自變數可以百分之百解釋依變數。
- Composite reliability (CR)是用來評估反應性模型reflective model中構造的內部一致性可靠性(評估收斂效度convergent validity的一個指標)。CR的值範圍在0到1之間,數值越高表示構造的內部一致性越好。根據Chin (1998) 和 Höck & Ringle (2006) 的標準,反應性模型中的CR至少要大於0.6。如果CR值低於0.6,則表明該構造缺乏內部一致性可靠性。
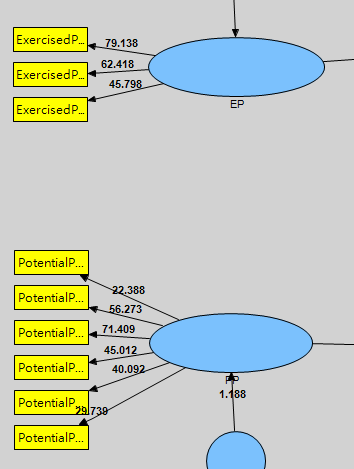
Fig1 
Step 2: 檢驗各路徑是否顯著,非常重要,前面只是告訴路徑係數和R Square,只是估計值而已。沒說這些路徑係數是不是顯著。
- 用Bootstrapping法 Bootstrapping就是去你提供的樣本裡再抽樣出一個新的樣本,用PLS Algorithm估計出我們剛才估計的所有東西(像是路徑係數),不斷重複這個步驟得到N組估計值,再用這N組的估計值來檢驗路徑係數能不能達到顯著水準。
程序: 選Bootstrapping-[No Sign Changes]子樣本的正負號必需要和原始樣本一樣-[Cases輸入你的樣本數量]-Samples[5000次]這個建議值可以得到比較穩定的結果。
3、檢視你的研究模型
- Bootstrapping結束後,會看到如下圖,路徑上所顯示的,是 t value告訴你,路徑是否顯著,那到底怎麼判斷?
t value>2.57 =顯著水準是1%,也就是p<0.01,就是非常顯著啦;
t value>1.96 =顯著水準是5%,就是 p<0.05,這是大家常用的標準,通常 t value要大於1.96才叫值顯著;
t value大於1.65,這代表顯著水準是10%,也就是p<0.1,這是最寬鬆的標準了。
Fig2 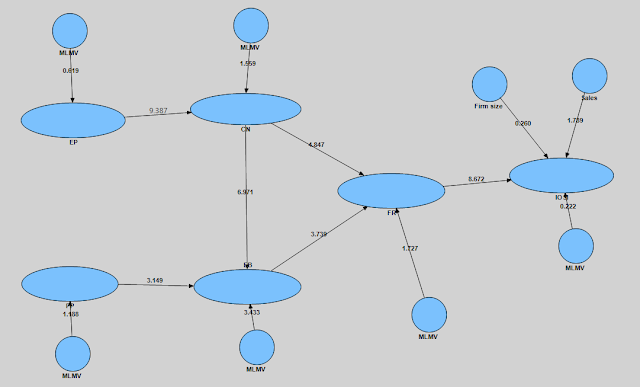
- indicators 和constructs之間loading值的顯著水準,通常所有的loading值,都必需要顯著;
Fig3